

La innovación corporativa como actitud para ser competitivos
Debemos adoptar un 'mindset' de innovación constante para impulsar la competitividad y sostenibilidad del negocio.
7 marzo, 2024
3 min
Artículo escrito por Irene Blasco Hernanz.
Nada más claro que un ejemplo de un proyecto real para comprobar la efectividad de las búsquedas conceptuales sobre la búsqueda por palabras clave gracias al machine learning. Fue hace ya unos cuantos años, cuando trabajé en un proyecto de competencia desleal en el que los responsables de una serie de empresas del sector de la alimentación quedaban de forma recurrente para tomarse un café juntos y, ya de paso, fijar los precios de ciertos productos según sus intereses.
Hasta aquí, éste podría describir el modus operandi de cualquier caso de estas características, pero lo curioso de éste es que, en todos los emails que intercambiaban y las citas de calendario donde agendaban estas reuniones, estos directivos hablaban de ello usando referencias del mundo del fútbol: “¿Dónde vamos a jugar el próximo partido?”, “Hoy le voy a sacar tarjeta roja a Pepe.”, “El último partido quedó 10-5”.
Lo que ahora es un chascarrillo cuando comentamos entre nosotros proyectos antiguos fue un verdadero quebradero de cabeza allá cuando iniciamos la investigación. Estas personas no hablaban de precios, ni de acuerdos, ni de reuniones, ni tan siquiera de los productos, ¡sólo hablaban de fútbol! ¡Y ni uno siquiera jugaba al fútbol en realidad! El 99% de nuestras búsquedas ciegas, basadas en palabras clave y expresiones booleanas, nos devolvían miles de correos electrónicos que poco tenían que ver con el hecho que estábamos intentando esclarecer.
Al contrario que una búsqueda por palabras clave, que fuerza a que dichas palabras se encuentren (o no) en el documento, hoy en día podemos aplicar búsquedas conceptuales.
Este tipo de búsqueda “interpreta” lo que el investigador quiere buscar, traduciéndolo al contexto en el que está lanzando la búsqueda. Es decir, son capaces de “entender” lo que el investigador está buscando y de encontrar documentos que respondan a esa petición incluso si están escritos con otras palabras.
Una búsqueda conceptual va más allá de ampliar la lista de palabras con sinónimos. Es poder preguntarle cualquier cosa a la máquina y que ésta te responda con los documentos que mejor se ajusten a la respuesta dentro del caso, así de simple y así de complejo al mismo tiempo.
En KPMG utilizamos Relativity, la herramienta de eDiscovery puntera que nos permite agilizar revisiones y aplicar funcionalidades avanzadas de análisis. Relativity tiene un complejo modelo matemático llamado Latent Semantic Indexing (LSI, por sus siglas en inglés) en el que se basa para construir un mapa conceptual.
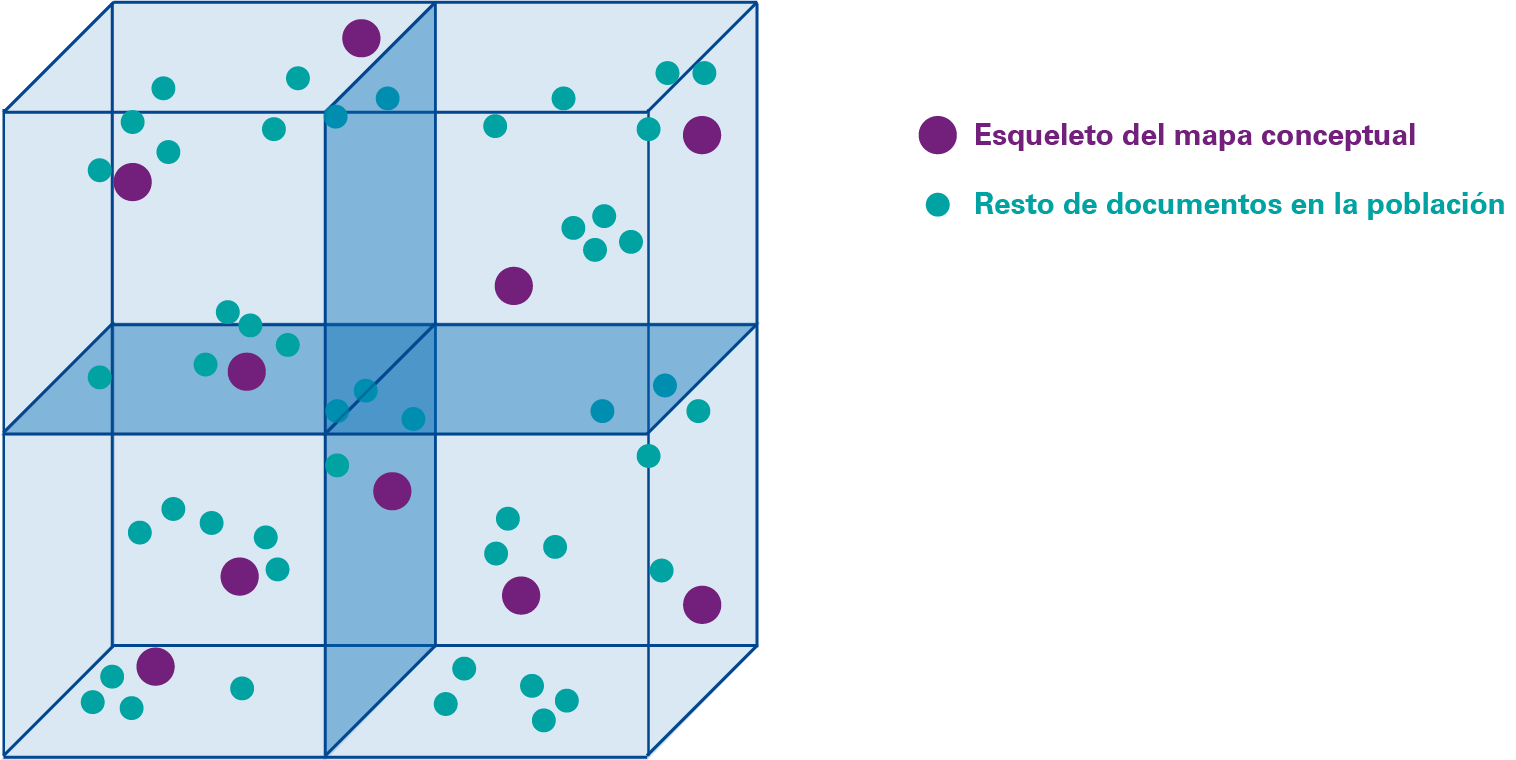
Simplificando, un mapa conceptual es como una jaula en la que cada documento ocupa un espacio concreto dependiendo de su contenido. Así, si dos documentos tienen conceptos similares, se situarán en este espacio uno cerca del otro. Sin embargo, si son de temática muy diferente, la distancia entre ellos será mayor.
En KPMG utilizamos los documentos de mayor calidad conceptual (archivos de Word, documentos PDF, correos electrónicos con un mínimo de texto…) para construir el esqueleto del mapa conceptual, para luego situar el resto de documentos según su parecido con estos primeros. El resultado es un Índice Conceptual, que es el motor sobre el que se lanzarán las diversas consultas, es decir, nuestras búsquedas conceptuales.
Veamos un ejemplo rescatando el proyecto que refería al principio, en el que los implicados hablaban en clave futbolística para fijar precios.
De haber existido las búsquedas conceptuales, habríamos utilizado el poder del Índice Conceptual para afrontar el caso siguiendo 2 aproximaciones:
El Cluster Wheel (o rueda de conceptos) es una representación gráfica e interactiva de todos los conceptos que Relativity puede encontrar en el caso.
Es especialmente útil cuando conocemos poco del caso y no sabemos por dónde empezar, porque nos da una idea de los temas que hay en nuestra población de datos. Además, nos permite ahondar a golpe de click en aquellas temáticas que nos parezcan más relevantes e, incluso, mandar directamente a revisión una sub-temática completa.
La animación a continuación muestra el aspecto de un Cluster Wheel:
El uso del Cluster Wheel nos habría ayudado sin duda a identificar una temática poco convencional en el mundo de la empresa, como puede ser la futbolística, pero sobre todo nos habría ayudado a descartar una población significativa de documentos (que en su día revisamos, perdiendo un valioso tiempo) que estaban relacionados con otros temas no concernientes con la investigación.
Esta funcionalidad de Relativity se apoya en el Índice Conceptual para expandir o ampliar los “significados” que tiene una palabra dentro del caso basándose en el Índice Conceptual.
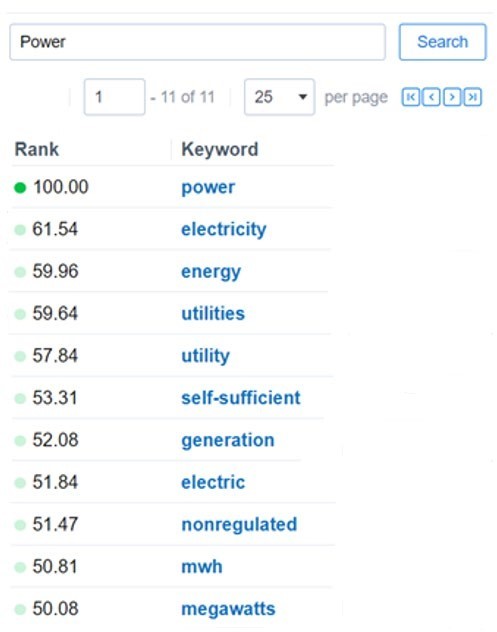
La imagen siguiente muestra un ejemplo de cómo Relativity presenta los resultados al buscar la palabra “power”. En este ejemplo, la herramienta devuelve aquellos términos conceptualmente relacionados con “power” junto a un valor, que es el peso de la correlación entre cada término y la palabra “power” en esa población de documentos en concreto.
Así, habríamos lanzado una serie de consultas a la máquina partiendo de las mismas palabras que utilizamos en su día (precio, fijar, competencia, CNMC, nombres de los supuestos implicados, etc.). Seguramente, estas consultas nos habrían devuelto un montón de términos relacionados con el día a día normal de los empleados de la empresa, pero también algún “partido” o “gol” que nos hubieran puesto sobre la pista desde el principio de la investigación. Y, partiendo ya desde un documento sospechoso, habríamos interrogado a la máquina sobre alguna frase en concreto, lo cual nos habría devuelto prácticamente toda la población de emails que finalmente usamos como evidencias para demostrar la trama.
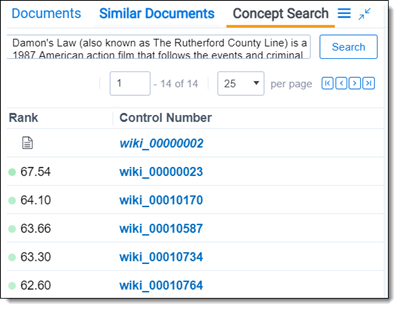
La imagen a continuación muestra un ejemplo de cómo consultar a la herramienta con una frase o párrafo relevante. En este caso, los resultados son los documentos que más se acerquen conceptualmente al párrafo consultado:
Como vemos, las búsquedas conceptuales nos permiten superar las limitaciones de las palabras claves como son las faltas de ortografía (“falsifcación” vs. “falsificación”), los homónimos (“comisión” en referencia a pago extra vs. “Comisión” en referencia a autoridad competente) o el uso del idioma según la región (Español de España vs. Español de Méjico, por ejemplo).
Las palabras claves continúan teniendo su importancia y siguen siendo fundamentales en el proceso investigador. Pero las técnicas de visualización y de búsquedas conceptuales si bien pueden resultar complejas de adoptar, son herramientas que sin lugar a duda están aquí para quedarse y evolucionar.
Las búsquedas conceptuales son solo una pequeña parte de la introducción del machine learning en el ámbito del eDiscovery. En próximos artículos comentaremos más funcionalidades que ofrece la inteligencia artificial y que van a cambiar la forma en que abordamos este tipo de proyectos para siempre.


Deja un comentario