Una de las tecnologías más importantes y que ha facilitado que hoy podamos hablar de IA es el machine learning. Pero ¿qué cabida tiene realmente en la función fiscal? ¿Qué puede hacer un fiscalista para integrar el ML en los procesos objeto de su responsabilidad? Para responder a esa pregunta conviene recordar que la inteligencia artificial integra, entre otros, varios conceptos como el propio machine learning, el aprendizaje profundo (eep learning), o las redes neuronales (neural networks).
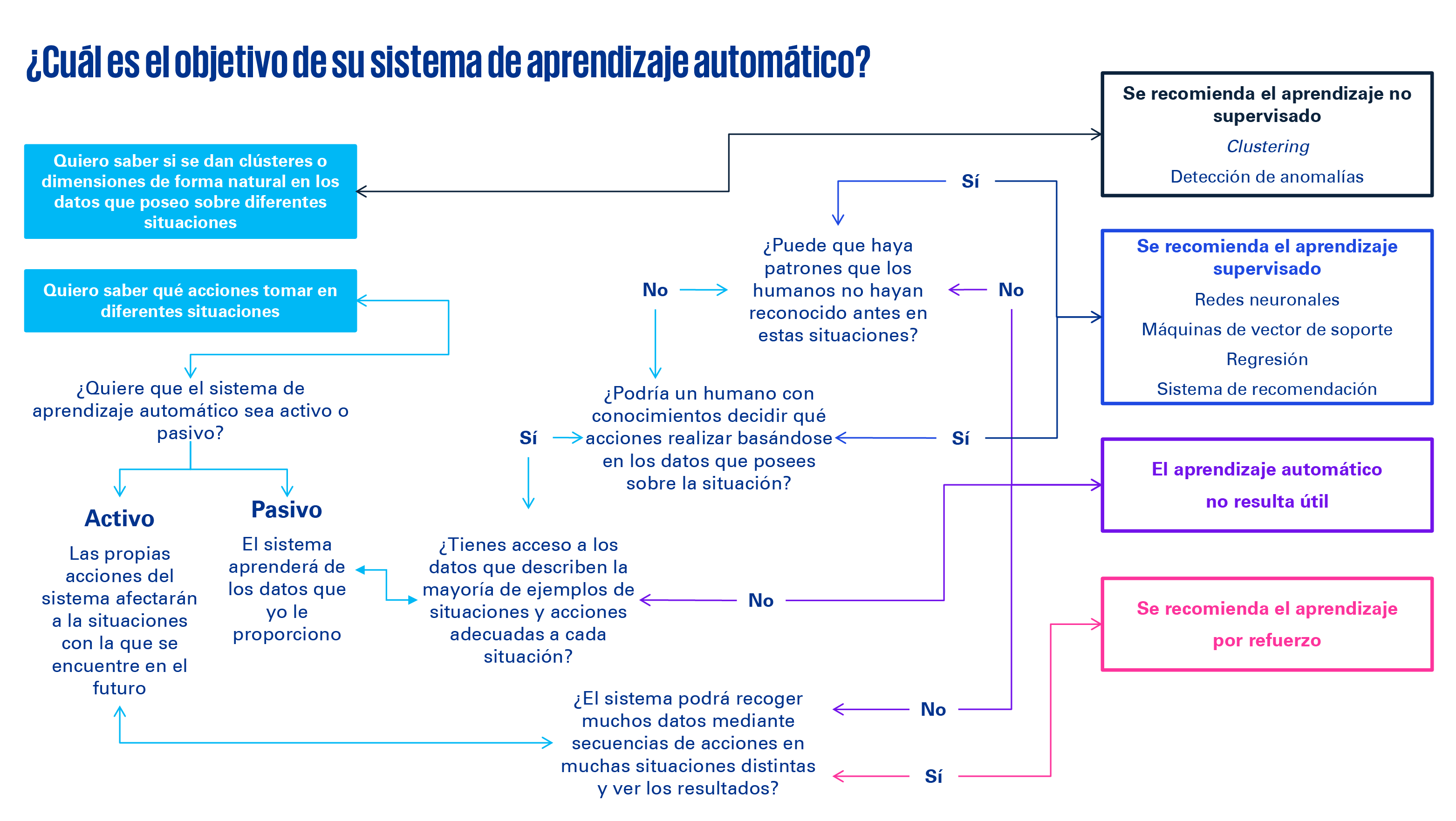
Mientras que la inteligencia artificial es la capacidad de un sistema informático para imitar las funciones cognitivas humanas, como el aprendizaje y la resolución de problemas, edentro del ML, encontramos tipos de modelos de aprendizaje que tienen aplicación en el desarrollo de la función fiscal: el supervisado, el no supervisado y el aprendizaje por esfuerzo.
ML supervisado: categorizando nuevos datos
Estos modelos utilizan sets de datos etiquetados con una categorización realizada previamente por seres humanos, lo que permite categorizar de forma automática nuevos datos. Con cada nueva ingesta de datos, el modelo puede aprender y ganar precisión con el paso del tiempo.
Esta tipología de aprendizaje puede ser utilizada en procesos de inspecciones fiscales. La información disponible derivada del histórico de litigios fiscales – entre otros, comunicaciones de inicio, diligencias, o actas de inspección – facilitan un colectivo de datos que puede ayudarnos a predecir resultados de inspección y hacer una prescripción de acciones a llevar a cabo dependiendo de variables como el equipo inspector o el alcance de la inspección. Se utilizan para tal fin algoritmos como los árboles de decisión, Naive Bayes, o la regresión logística.




Deja un comentario